The secret to successful AI monitoring: Get granular, but avoid noise
In the past 4 years I’ve been working with teams implementing automated workflows using ML, NLP, RPA, and many other techniques, for a myriad of business functions ranging from fraud detection, audio transcription all the way to satellite imagery classification. At various points in time, all of these teams realized that alongside the benefits of automation they have also added additional risk. They have lost their “eyes and ears on the field”, the natural oversight you get by having humans in the process.
Now, if something goes wrong, there isn’t a human to notify them, and if there’s a place in which an improvement could be made, there might not be a human to think about it and recommend it. Put differently, they realized that humans weren’t only performing the task that is now automated, they were also there, at least partially, to monitor and QA the actual workflow. While each business function is different, and every automation or AI that is used has its own myriad of intricacies and things requiring monitoring and observing, one common thread binding all of these use-cases is that issues and opportunities for improvement usually appear in pockets, as opposed to grand sweeping, across the board.
Granular tracking is key to finding issues and opportunities
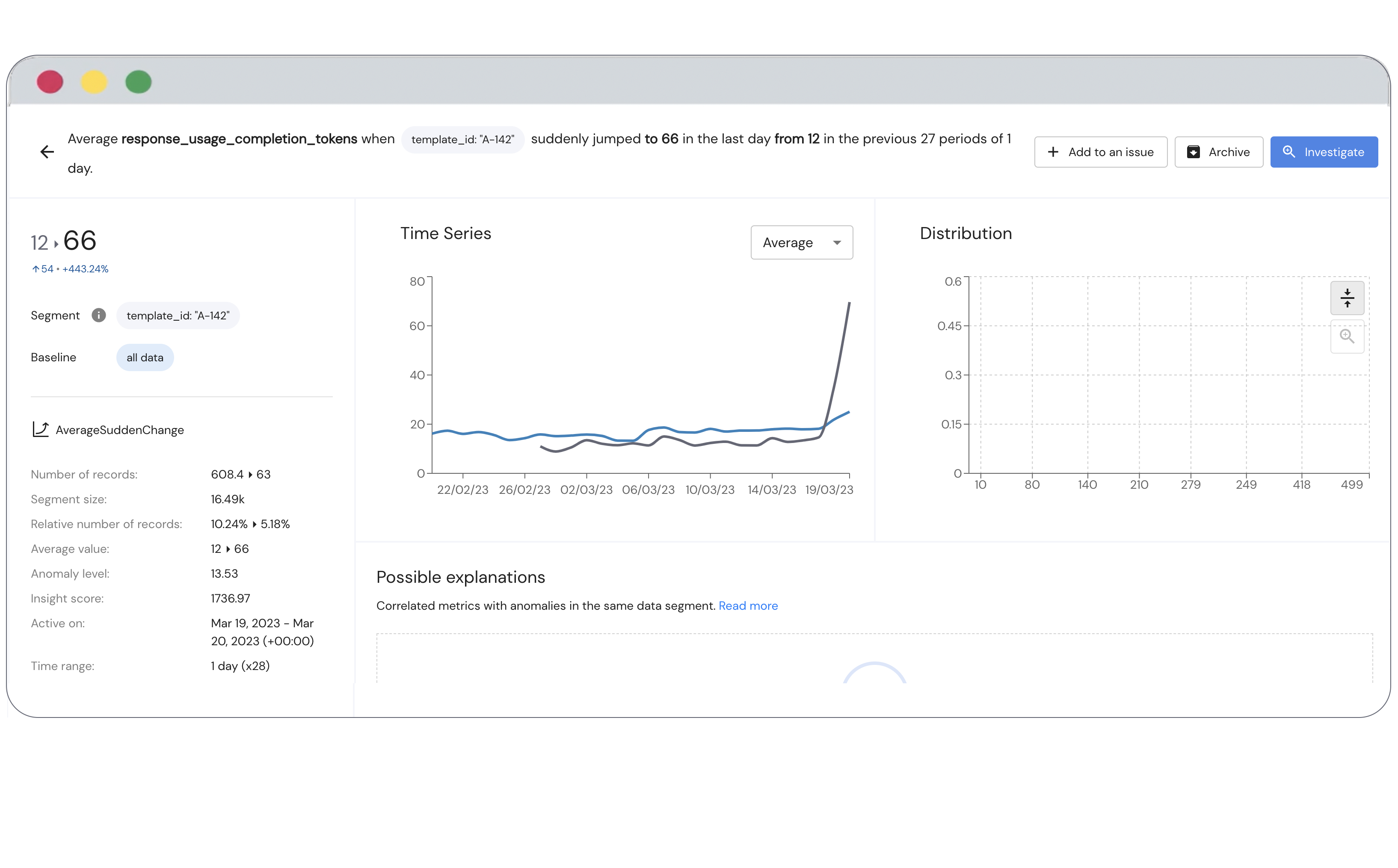
Let’s elaborate a bit about those pockets in which problems/opportunities arise. Imagine you have a fraud detection system. In order for this system to work properly, you use input data extracted from cookies on the user’s browser. Now, assume that there is a new beta version of the Chrome browser. In this version, cookies are stored in a slightly different way. This could break your fraud predictors that use cookie data. Luckily, this only happens for a small percentage of your traffic, since this new version is beta and isn’t widely adopted yet. But over time, this beta version will become the de facto version and may account for a major part of your traffic. This could be a problem. If you monitor this fraud detection system, would you uncover this issue early enough? Only if you monitor at a granular, meaning, only if you automatically track the performance of your fraud predictors at the browser version level.
Granular tracking that leverages new information could be a powerful bias detector
Now, imagine you have a machine learning model that detects the language spoken in conversations (i.e. audio files). You trained one variant of this model to detect French, leveraging a dataset of French conversations. Unbeknown to you - there’s a bias in the training set. A specific region in France, in which the accent is particular, isn’t well represented. This model is production grade, and in production, new inputs (for inference) include geographical information. You can tell which regions new conversations come from. So the bias in the training set could be uncovered, but only if you’re leveraging the new available dimensions to automatically track the relevant KPIs (e.g., the model’s output confidence) in each of the regions. If you’ve implemented this level of AI monitoring, you can be alerted about an underperforming region and tie that back to the biased dataset.
The challenge with granularity - Noise
Now, say that you’ve done the work and implemented granular monitoring for your system. You instantly get alerted on any data segment in which there is some underperformance or anomalous behavior. Not an easy task on its own, but the problem now is that you’d get too many alerts and won’t know what to do with them. The reason for all this noise is that one anomaly in the data could manifest in many ways. Said differently, many apparent anomalies may be correlated to one root problem, the culprit. To explain, let’s take the French-speaking region bias discussed in the previous paragraph. By model monitoring in a granular way, you might encounter 5 different customers whose data originates from this region. Since you now get alerts on any customer in which there is underperformance - you’d get 5 extra alerts. But the real problem with all these customers is well described just by looking at the region. To avoid getting alerted 6 times and consequently suffering from alert fatigue, you must have some mechanism to understand that all these “customer-specific” issues are actually an issue within a single region and should get alerted only once.
Summary
In my experience, the current state of our industry is as follows:- AI or automation teams, across all business verticals, either have workflows and processes that are grossly under-monitored or they’re trying to build monitoring in house and are overwhelmed by the amount of noise.
- In the former, I also include teams who have bought and deployed most existing AI monitoring solutions in the market, as those provide only basic intelligence, looking at features and outputs across all of the data, and alerting you on “drifts” only when it’s too late.
- As we’ve seen in the examples above, real issues occur and must be caught within specific sub-populations of your data, and alerting when something changes overall just doesn’t prevent hurting your business KPIs or help you improve over time.