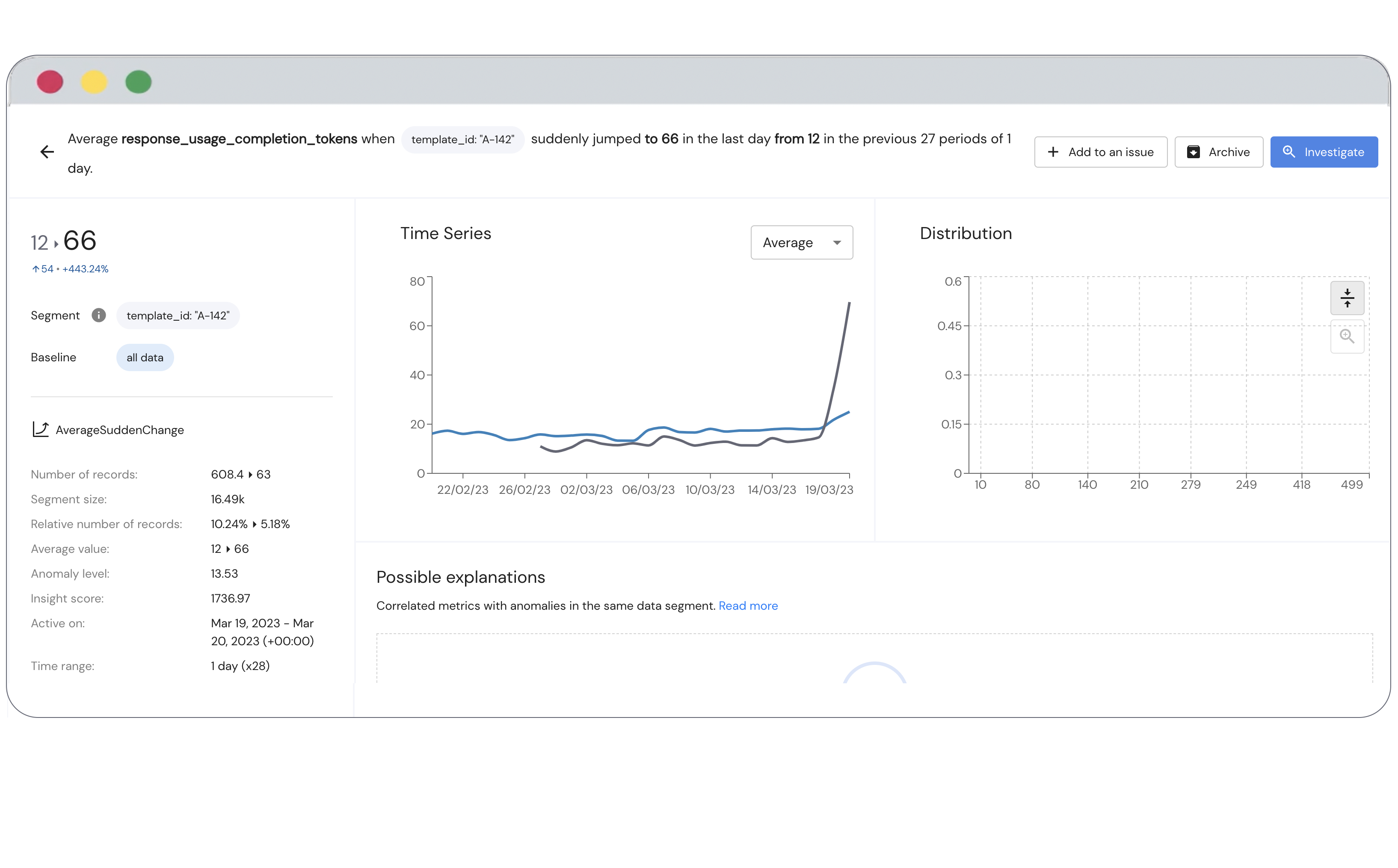
Should you use ML monitoring solution offered by your cloud provider?
As AI systems become increasingly ubiquitous in many industries, the need to monitor these systems rises. AI systems, much more than traditional software, are hypersensitive to changes in their data inputs. Consequently, a new class of AI monitoring solutions has risen at the data and functional level (rather than the infrastructure of application levels). These solutions aim to detect the unique issues that are common in AI systems, namely concept drifts, data drifts, biases, and more.
The AI vendor landscape is now crowded with companies touting monitoring capabilities. These companies include best-of-breed/standalone solutions, and integrated AI lifecycle management suites. The latter offers more basic model monitoring capabilities, as a secondary focus.
To further the hype, some of the major cloud providers began communicating that they also offer monitoring features for machine learning models deployed on their cloud platforms. AWS and Azure, the largest and 2nd largest providers by market share, each announced specific features under the umbrellas of their respective ML platforms - SageMaker Model Monitor (AWS), and Dataset Monitors (Azure) respectively. Google (GCP), so far, seems to only offer application-level monitoring for serving models and for training jobs.
In this post, we provide a general overview of the current offerings from the cloud providers (we focused on AWS and Azure) and discuss the gaps in these solutions (which are generally covered well by best-of-breed solutions).
An overview of the cloud providers offerings
So what do Azure and AWS have to offer regarding monitoring models in production?
Log model inputs and outputs with a flip of a switch
The first part of monitoring any kind of system is almost always logging data from the operation of the system. In the case of monitoring ML models, this starts with the model inputs and outputs.
Unsurprisingly, both Azure and AWS allow you to easily log this data to their respective data stores (S3 buckets for AWS, blob storage for Azure). All you have to do is add a data capturing configuration to the model run call in your python code. Note that not all input types can be automatically saved (e.g., on Azure, audio, images, and video are not collected). AWS allows configuring a sampling rate for the data capturing as well.
Analyzing the data using existing analytics and APM solutions
Once the input and output data is collected, the next step suggested by the platforms is to use their existing analytics/APM offerings to track the data.
Azure recommends using Power BI or Azure DataBricks to get an initial analysis of the data, while in AWS you could use Amazon Cloudwatch.
Since the data is saved in the platform’s own storage system, it is usually pretty straightforward to get initial charts and graphs tracking your model’s inputs and outputs.
Basic tracking of the input data for drift
Both AWS and Azure offer fairly new tools for alerting on changes in the distribution and behavior of your model’s input data. For AWS this is the main part of “Amazon SageMaker Model Monitor”, whereas for Azure this is done via a very new feature called “Datasets Monitors”.
On both platforms, the workflow starts by creating a baseline dataset, which is usually based directly on the training dataset.
Once you have that baseline ready, the platforms allow you to create datasets from inference input data captured as described above, compare them to the baseline dataset, and get reports on changes in the feature distributions.
There are some differences between the two solutions. AWS’ solution creates “constraints” and “statistics” files from the baseline data set, which contain statistical information on the input data. This allows you to later compare to inference data to get reports on differences. On the other hand, Azure’s “Dataset Monitors” provides you with a dashboard comparing the distributions of each feature between the baseline dataset and the inference time one. It then allows you to set up alerts for when the change in distribution is large enough.
However, the above differences are really implementation details for the same basic functionality - take your feature set, look at their baseline distribution in your training set, and compare it to their distribution in inference time.
Is that enough?
So, the cloud providers do offer AI monitoring capabilities for the data and model layer, but can you rely on these capabilities to sustain and even improve upon a production-grade AI system? We believe that you cannot. Here are a few reasons for that:
Rich, contextual data is needed for production-grade AI monitoring
Tracking your model inputs and outputs is good, but it’s not enough to really understand your data and models’ behaviors. What you really need to observe isn’t a single model - but an entire AI system. Many times, this will include data your cloud provider cannot easily access.
A few examples:
-
You have a human labeling system, and you’d like to monitor how your ML model’s output compares to their labeling, to get real performance metrics for your model.
-
Your system contains several models and pipelines, and one of the models’ output is used as an input feature for a subsequent model. Underperformance in the first model may be the root cause for underperformance in the second model, and your AI monitoring system should understand this dependency and alert you accordingly.
-
You have actual business results (e.g., whether the ad your suggestions model chose was actually clicked) - this is a very important metric to measure your ML model’s performance, and is relevant even if the input features never really changed.
-
You have metadata that you don’t want (or even not allowed, e.g., race/gender) to use as an input feature, but you do want to track it for observability, to make sure you are not biased on that data field.
For more on context-based monitoring - check out this post about the platform approach to monitoring.
Tracking sub-segments of your data
It is not uncommon for an AI system to work just fine on average, but grossly underperform on sub-segments of the data. So, a granular examination of performance is crucial.
Consider a case where your ML model behaves very differently on data coming from one of your customers. If this customer accounts for 5% of the data your model ingests, then the overall average performance of the ML model might seem fine. This customer, however, will not be pleased. The same could be true for different geolocations, devices, browsers or any other dimension along which your data could be sliced.
A good AI monitoring solution will alert you when anomalous behavior in sub-segments happens, including when it happens in more granular sub-segments, e.g., for users coming from a specific geo using a specific device.
Configurability
Every AI system is like a snowflake. They all have specific performance metrics, acceptable (or unacceptable) behaviors, etc. A good AI monitoring platform must therefore be highly configurable.
Consider a case where you have an NLP model detecting the sentiment of input texts. You know that on short texts (e.g., below 50 characters), your ML model isn’t very accurate, and you’re OK with this. You’d like to observe your model outputs, but you don’t want to be alerted on low confidence scores when there’s an increase in the relative proportion of short input texts. Your ML monitoring platform must allow you to easily exclude all short texts from the monitored dataset, when considering this specific metric (but maybe not for other metrics).
There are many other examples that illustrate the value of fine-tuning, ranging from alerting preferences to ad-hoc data manipulations. The completely autonomous AI monitoring approach sounds good in theory and is easy to explain, but will fail when encountering real-world constraints.
Conclusion
First, it is encouraging to see the major cloud providers beginning to provide more tooling for production AI. Nevertheless, the solutions we reviewed were quite basic and experimental (Azure, for example, does not yet provide any SLAs for the above mentioned solution). ML monitoring certainly does not feel like a top priority for these providers.
At the same time, it is becoming increasingly clear in the industry that monitoring models and the entire AI system is a foundational need that cannot be treated as an afterthought. It is crucial to get this right in order to make your AI production-ready and to make sure AI issues are caught before business KPIs are negatively impacted. The best-of-breed solutions have certainly made AI monitoring their core focus and priority.
So, will best-of-breeds have an advantage in the market? It remains to be seen. One possible precedence to consider is that of the APM industry. The cloud providers have long had rudimentary solutions for IT organizations, and yet the market gave rise to a successful category of best-of-breed players such as New Relic, AppDynamics, and Datadog (and quite a few others). Some buyers settle for more basic capabilities as they prefer to deal with fewer vendors, whereas others prefer the most in-depth capabilities in every stage of the life cycle.
In any event, the evolution of this category will surely be interesting to observe and experience. If you're interested in learning about how our flexible AI monitoring solution can benefit your business, sign up for a free trial or schedule a demo.
References
-
GCP monitoring models (APM like): https://cloud.google.com/ai-platform/prediction/docs/monitor-prediction
-
AWS announces (Dec 19) “Sagemaker Model Monitor”: https://aws.amazon.com/blogs/aws/amazon-sagemaker-model-monitor-fully-managed-automatic-monitoring-for-your-machine-learning-models/
-
Azure model data collection: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-enable-data-collection
-
Azure Dataset monitors: https://aws.amazon.com/blogs/aws/amazon-sagemaker-model-monitor-fully-managed-automatic-monitoring-for-your-machine-learning-models/