If you’ve been struggling to get some transparency into your AI models’ performance in production, you’re in good company. Monitoring complex systems is always a challenge. Monitoring complex AI systems, with their built-in opacity, is a radical challenge.
With the proliferation of methods, underlying technologies and use cases for AI in the enterprise, AI systems are becoming increasingly unique. To fit the needs of their business, each data science team ends up building something quite singular; every AI system is a snowflake.
The immense diversity of AI techniques, use cases and data contexts voids the possibility of a one size fits all monitoring solution. Autonomous monitoring solutions, for example, are often insufficient because they naturally don't extend beyond a handful of use cases. It’s a big challenge for these solutions to extend or scale because to monitor AI systems without user context one has to make a lot of assumptions about the metrics, their expected behavior, and the possible root causes of changes in them.
An obvious fix is to build autonomous point solutions for each use case, but this won't scale. So is there a framework or solution designed to work for (almost) everyone?
YES. It's the Platform Approach.
The Platform Approach to monitoring the black box
The Platform Approach to AI system monitoring is the sweet spot between the generic autonomous approach, and the tailored approach, built-from-scratch. This means that on the one hand the monitoring system is configured according to the unique characteristics of the user’s AI-system, but on the other hand, it can effortlessly scale to meet new models, solution architectures and monitoring contexts.
This is achieved by implementing common monitoring building blocks, that are then configured by the user on the fly to achieve a tailored, dedicated monitoring solution. This monitoring environment works with any development and deployment stack (and any model type or AI technique). And, since the monitoring platform is independent and decoupled from the stack it enables a super swift integration that doesn’t affect development and deployment processes, and, even more importantly, monitoring that cuts across all layers in the stack.
The configurability of the system means that data teams aren’t limited to a prefabricated definition of their system: they are actually empowered by an “engineering arm” that gives them full control of the monitoring strategy and execution.
A flexible, adaptable solution
Beyond the fact that the Platform Approach can solve the monitoring problem for the industry, its endless flexibility benefits the user in ways that are not available in an industry specific autonomous solution. This might sound like a counter-intuitive assumption, so here are a few examples to the kind of features inherent in an agnostic system that are simply unattainable through autonomous solutions, even when those are industry specific:
Monitor by context (or system), not by model.
If you have ground truth (or objective feedback on success/failure) available some time after the model ran, you'd want to correlate the new information with the info captured at inference time. An example for this kind of scenario is a marketing campaign targeting model that receives feedback on the success of the campaign (conversion, CTR, etc.) within a few weeks. In such a use case we would want the monitoring to be able to tie between the model’s predictions and the business outcome.
Monitoring by context can also be invaluable if you're comparing two different model versions running on the same data (in a "Shadow Deployment" scenario).
If you have multiple models that run in the same data context and perhaps depend on one another, you need to have a way to infer whether the true root cause for a failure in one model relates to the other. For example, in an NLP setting, if your language detection model deteriorates in accuracy, the sentiment analysis model downstream will likely underperform as well.
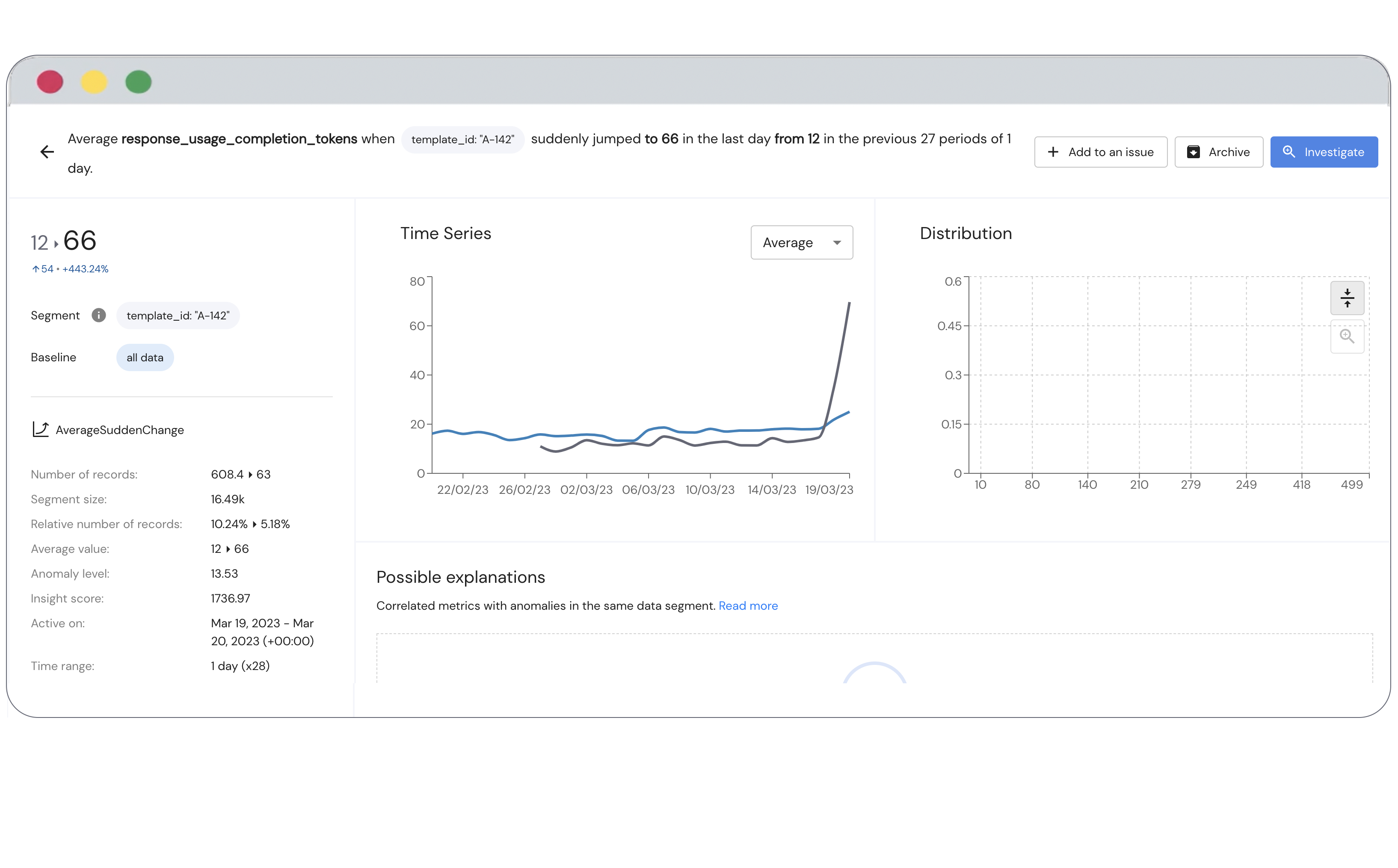
Configure your anomaly detection.
Anomalies are always in context, so there are many instances in which an apparent anomaly (even underperformance) is acceptable, and the data scientist can dismiss it. The ability to configure your anomaly detection means that the monitoring solution won't simply detect generic underperformance, but rather define what custom-configured anomalies might indicate underperformance.
 Three anomaly categories that are prominent in AI monitoring: Outlier (Left), Drift (Center), Sudden Change (Right)
Three anomaly categories that are prominent in AI monitoring: Outlier (Left), Drift (Center), Sudden Change (Right)
For example: You analyze the sentiment of tweets. The monitoring solution found reduced prediction confidence on tweets below 20 characters (short tweets). You might be okay with this sort of weakness (e.g., if this is in line with customer expectations). Your monitoring solution should then enable you to exclude this segment (short tweets) from the analysis to avoid skewing the measurement for the rest of the data (which is particularly important if short tweets account for a significant part of the data).

Track any metric, at any stage.
Most commonly, teams would track and review model precision and recall (which require “labeled data”). Even when there's no such "ground truth", there could be a lot of non-trivial indicators to track which could indicate model misbehavior. For example: If you have a text category classifier, you may want to track the relative prevalence of tweets for which no category scored above a certain threshold, as an indicator for low classification confidence. This kind of metric needs to be calculated from the raw results, so it's non-trivial and won't be "available" out of the box.
In addition, every metric can be further segmented according to numerous dimensions along which the behavior of the metrics might change (for example if your metric is the text classification confidence, then a dimension might be the text’s length or the language in which the text is written.)
Furthermore, if you're just looking at model inputs and outputs, you're missing out on dimensions that might not be important for your predictions but are essential for Governance. For example: Race and gender aren’t (and should never be) features in your loan algorithm, but they're important dimensions along which to assess the model's behavior.
No one knows your AI better than you
A robust monitoring solution that can give you real, valuable insights into your AI system needs to be relevant to your unique technology and context and flexible to accommodate your specific use cases and future development needs.
Such a system should be stack agnostic, so you’re free to use any technology or methodology for production and training. It needs to look at your AI system holistically, so that specific production and performance areas are viewed not as silos but in the context of the overall system. And most importantly, it needs to look at your system in your unique backdrop — that only you can provide and fine-tune. The Platform Approach to AI monitoring is aimed at achieving just that.
If you're interested in learning about how our flexible AI monitoring solution is different than your out of the box solution, sign up for a free trial or you can get an in-depth walkthrough of our platform by requesting a demo.